火车头简介
火车采集器官网 - 网页抓取工具火车头采集器免费网站采集软件
火车采集器,一款专业的互联网数据抓取、处理、分析,挖掘软件,可以灵活迅速地抓取网页上散乱分布的数据信息,并通过一系列的分析处理,准确挖掘出所需数据。火车采集器历经十二年的升级更新,积累了大量用户和良好口碑,是目前最受欢迎的网页数据采集软件。
简单来讲,就是使用软件来简化我们的爬虫过程,在整一个过程中,不需要编写代码就能够实现爬虫逻辑。
举例爬取任务
需要分页爬取所有页面,并对页面上所有感兴趣的条目进一步爬取二级 URL
新建任务
添加一个任务
网址采集规则 - 网址获取
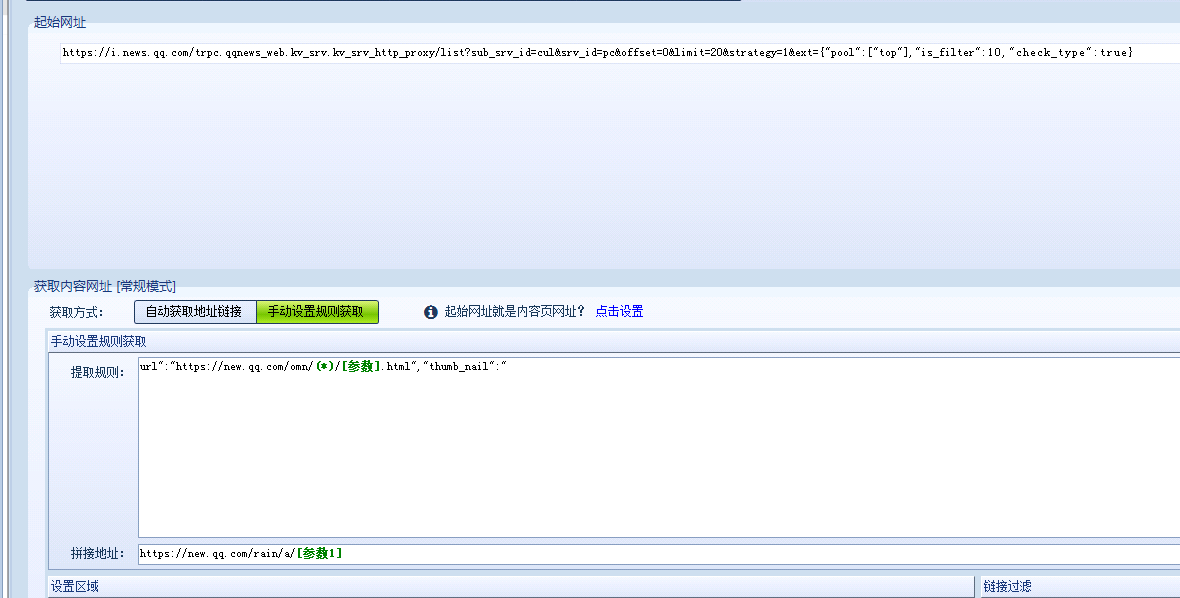
起始网址填上【第一页的 URL】
网址获取选项的意思:提取当前页面上想要爬取的条目的 URL,比如 xx 网第一页上的符合条件的所有商品链接。
<div class="Z_list-box"> ... <div class="pic-box"> <a href="//test.com/4343434333555.html" target="_blank" class="pic-wrap" ><img class="lazy" alt="立白洗衣液" style="display: inline" /></a> <span class="ico ico-video"></span> </div> <div class="pic-box"> <a href="//test.com/434322425.html" target="_blank" class="pic-wrap" ><img class="lazy" alt="外星人鼠标" style="display: inline" /></a> <span class="ico ico-video"></span> </div> ... <div class="Z_pages" id="page">
比如当前网页的源码是这样的,想要获取这两件商品的链接,分析网页源码可知商品的链接为 //test.com/xx.html ,我们要提取的链接就是这个
在提取规则里面填入 <div class="pic-box">(*)href="[参数]" 这里的 <div class="pic-box"> 代表内容开头的地方;(*) 代表匹配所有内容,href="[参数]" 代表内容结束,[参数] 则表示想要提取的内容,也就是这里的链接。简而言之,就是指定搜查的区域,然后使用 [参数] 提取出内容。
设置区域可以减少噪音,避免爬取区域外的内容
网址采集规则 - 分页设置
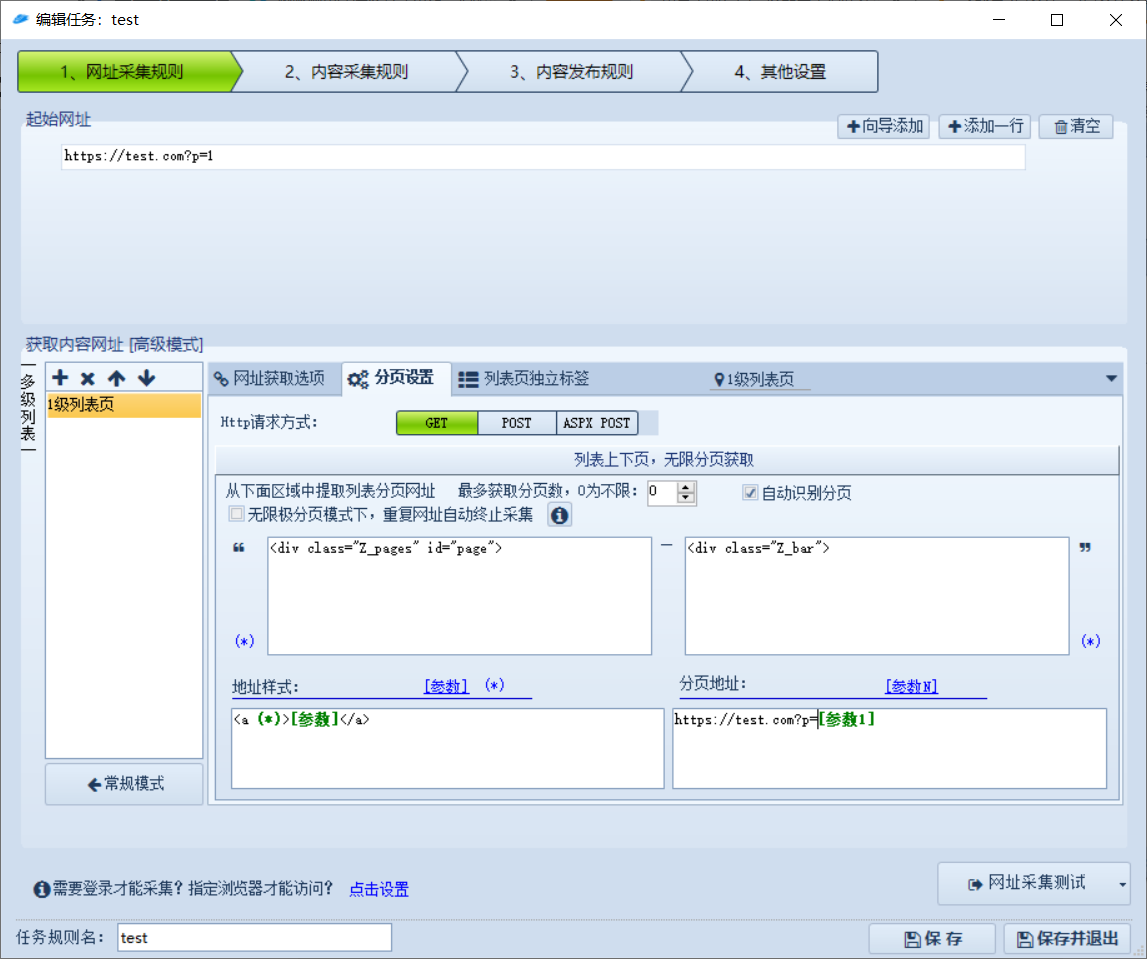
这里主要设置分页规则,表示不仅要爬当前页,还要爬取所有的页面
打开无限极分页:任务可以重复运行,如果 URL 已经爬取过了,那么就不会对该 URL 执行任务,该选项一般是关闭的,因为我们想要想要不断爬取从而不断获取到新的信息
区域开始结束位置:无限极分页模式下面的两个输入框就是指定获取下一页位置的开始结束区域
html<div class="Z_pages" id="page"> <a href="//test.com?p=2" >2</a > <a href="//test.com?p=3" >3</a > <a class="next" href="//test.com/next" >下一页</a > </div> <div class="Z_bar"> ... </div>
地址样式:这里用来提取第几页,比如 <a (*)>[参数]</a> ,参数会提取出数字 2、3
分页地址:地址的拼接规则
这里可以看到分页信息区域的开始结束位置为 <div class="Z_pages" id="page"> <div class="Z_bar">
内容采集规则
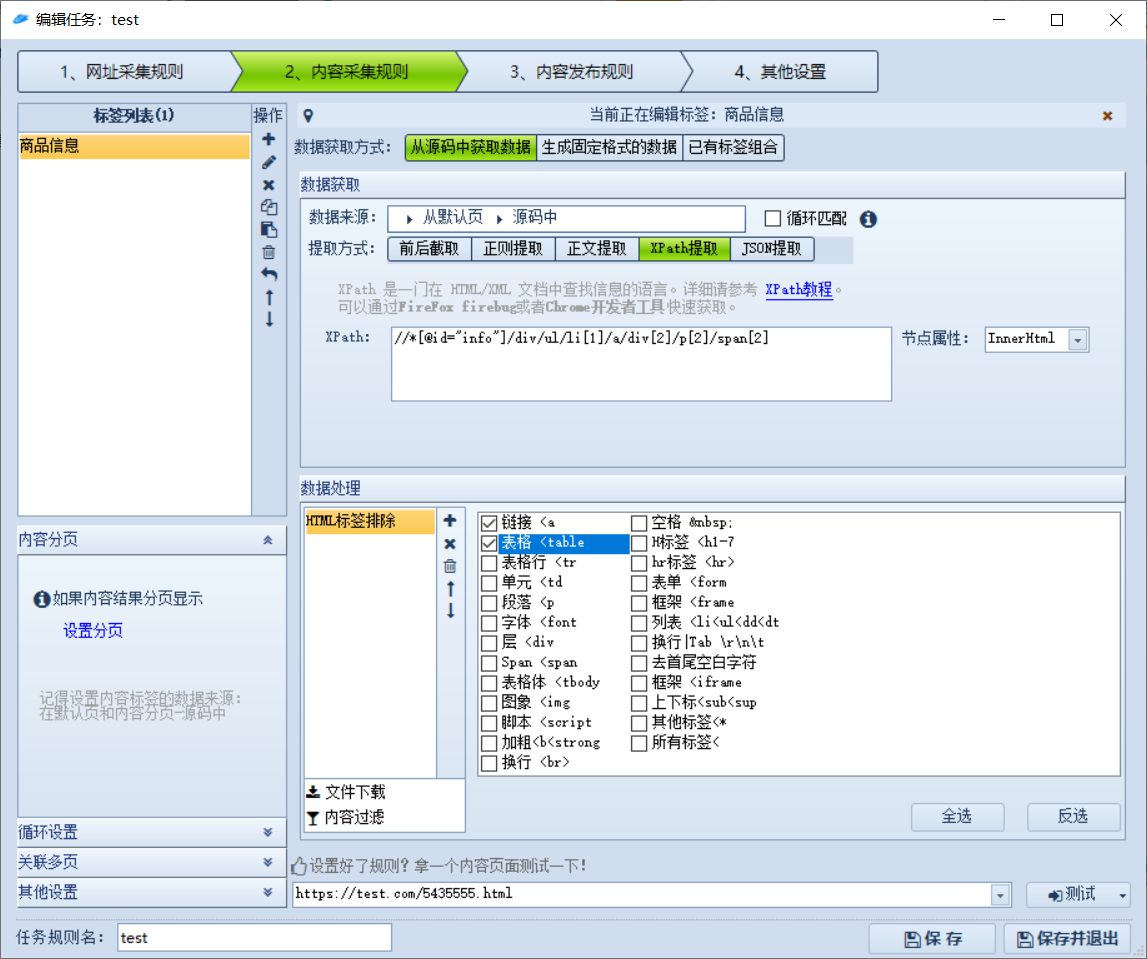
这里设定对前面采集到的 URL 里面的内容提取的规则,也就是一个个商品详情页的内容
这里一般设置为从源码获取数据,使用 XPath 提取,因为这个规则可以直接从 Chrome 中复制粘贴,比较方便
对采集到的内容可以进一步,比如去除 HTML 标签,数据为空跳过等等
设置好规则后可以填入某一个页面测试提取的规则是否正确
内容发布规则
用来指定采集到的内容怎么处理,这里是设置为发送到某个 api
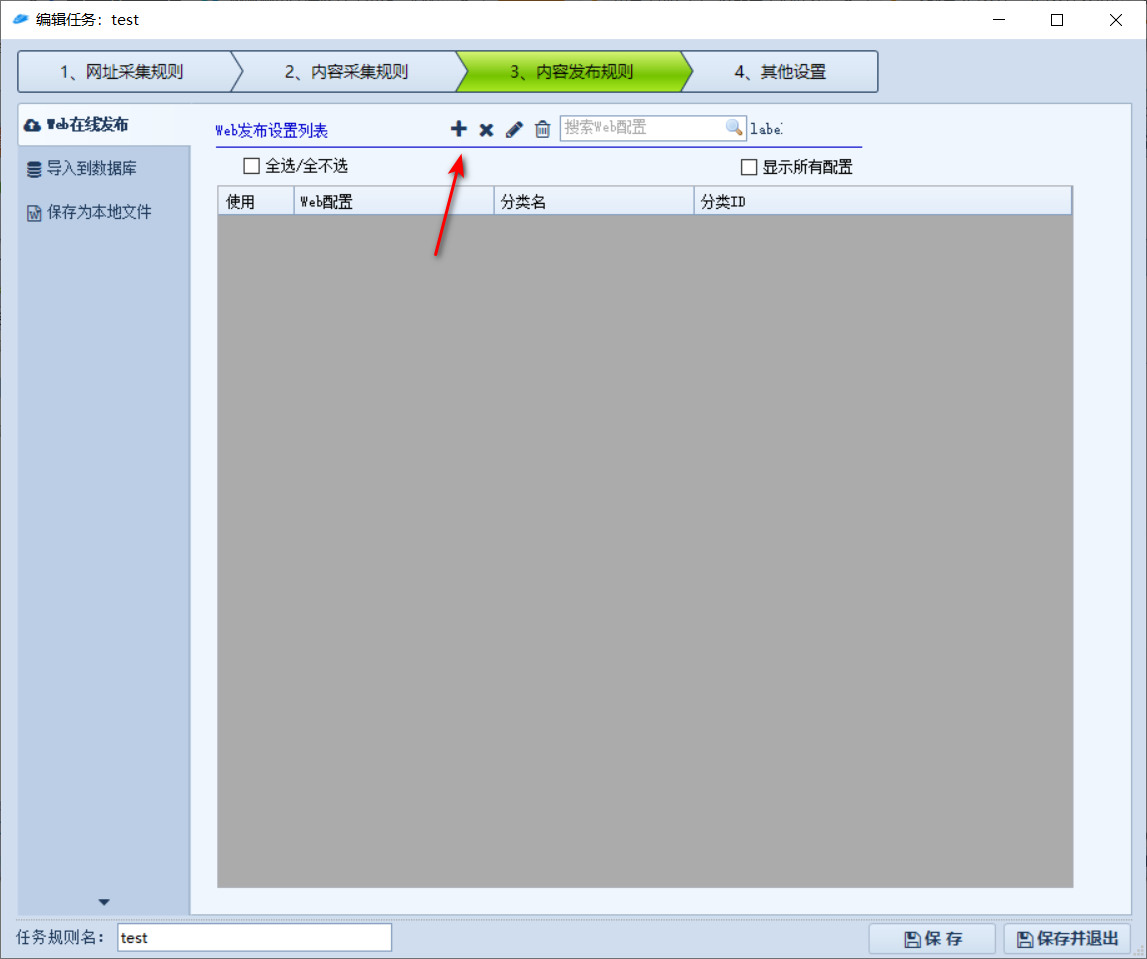
点击 + 号添加规则
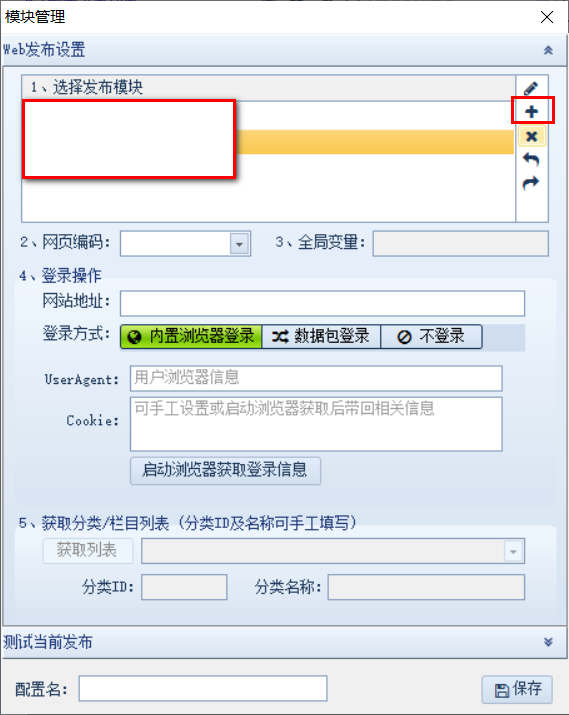
新建发布模块
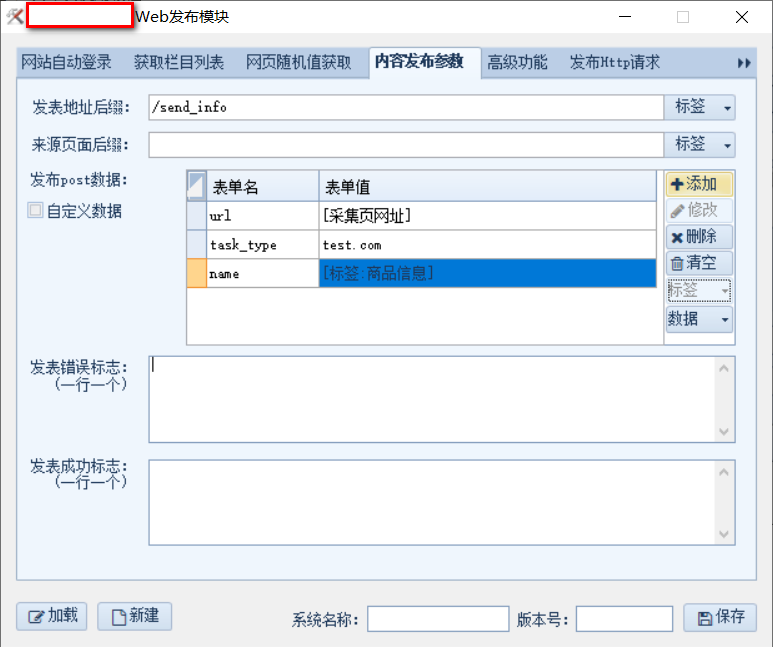
这里指定想要发送给 api 的参数,其中 name 就是在【内容采集规则】部分获取到的信息,参数为规则名。
其他设置不用动即可,直接保存。
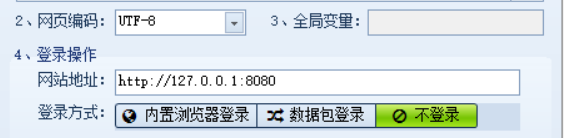
接着填入请求的 host 即可
其他设置
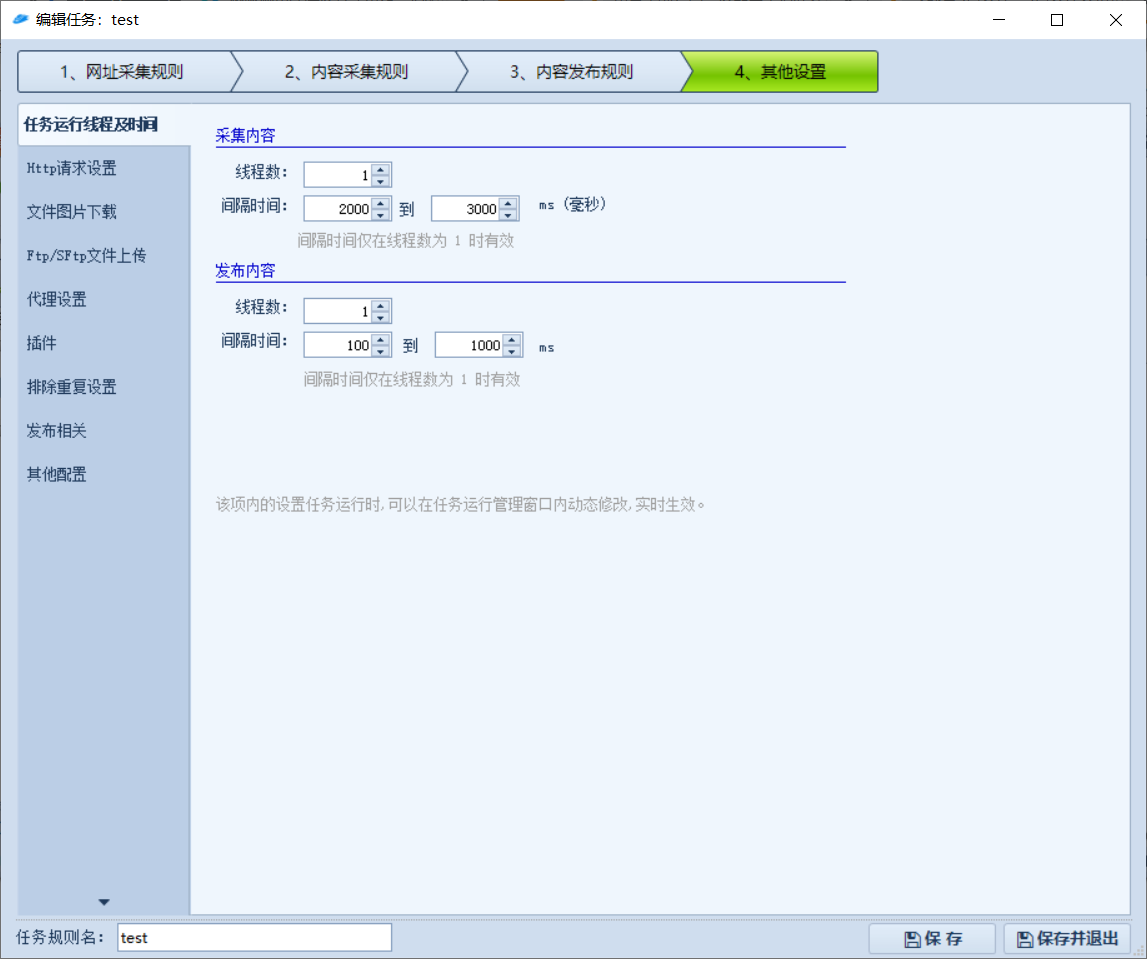
这里有一些常用设置,可选。
查看爬取到数据
定时任务设置
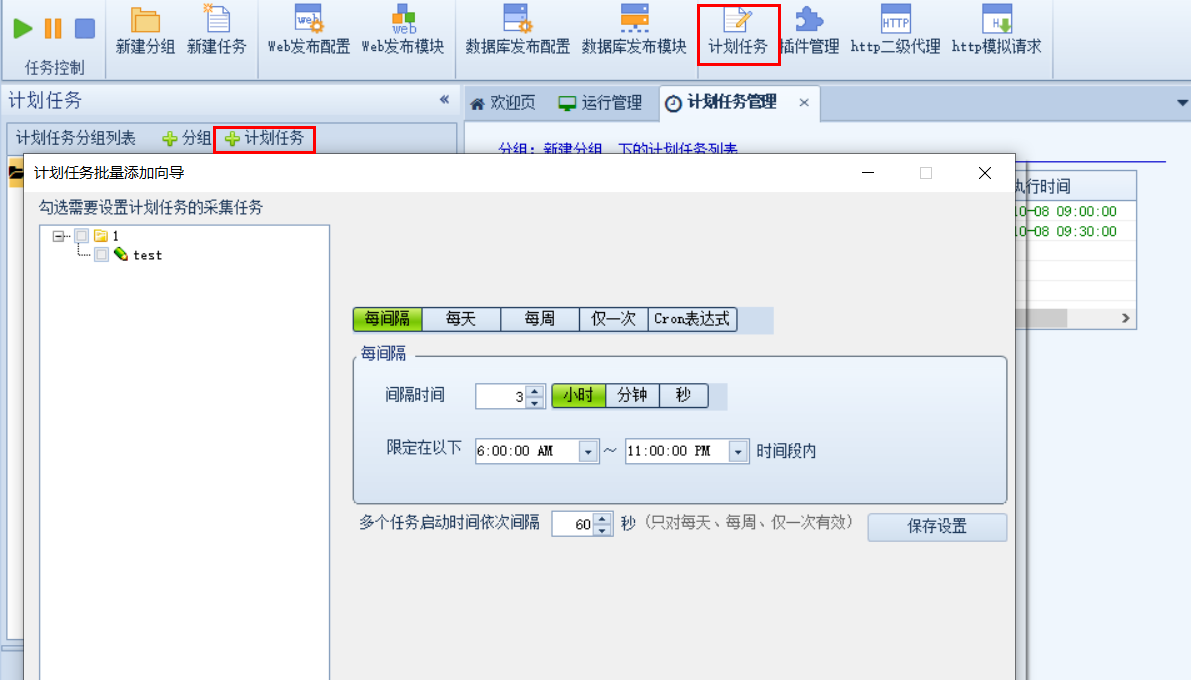
这里可以指定任务重复运行的规则

为您推荐